 Databricks stellt Weiter-entwicklungen der Databricks-Lakehouse-Plattform vor. Dazu gehören eine Optimierung der Data-Warehousing-Leistung und -Funktionalität, erweiterte Data-Governance, neue Innovationen für die gemeinsame Nutzung von Daten, darunter ein Marktplatz für Analysen und Daten-Cleanrooms für eine sichere Zusammenarbeit, automatische Kostenoptimierung für ETL-Operationen und Verbesserungen im Lebenszyklus von maschinellem Lernen.
Databricks stellt Weiter-entwicklungen der Databricks-Lakehouse-Plattform vor. Dazu gehören eine Optimierung der Data-Warehousing-Leistung und -Funktionalität, erweiterte Data-Governance, neue Innovationen für die gemeinsame Nutzung von Daten, darunter ein Marktplatz für Analysen und Daten-Cleanrooms für eine sichere Zusammenarbeit, automatische Kostenoptimierung für ETL-Operationen und Verbesserungen im Lebenszyklus von maschinellem Lernen.
„Unsere Kunden möchten Business-Intelligence, KI und maschinelles Lernen auf einer Plattform durchführen können, auf der sich ihre Daten bereits befinden. Dies erfordert erstklassige Data-Warehousing-Funktionen, die direkt auf ihrem Data Lake ausgeführt werden können. Im Benchmarking mit den höchsten Standards haben wir immer wieder bewiesen, dass die Databricks-Lakehouse-Plattform Datenteams das Beste aus beiden Welten auf einer einfachen, offenen und Multi-Cloud-Plattform bietet“, sagt Ali Ghodsi, Mitbegründer und CEO von Databricks. „Die heutigen Ankündigungen sind ein bedeutender Schritt in der Weiterentwicklung unserer Lakehouse-Vision, da wir es schneller und einfacher denn je machen, den Wert von Daten zu maximieren, sowohl innerhalb als auch zwischen Unternehmen.“
Das beste Data-Warehouse ist das Lakehouse
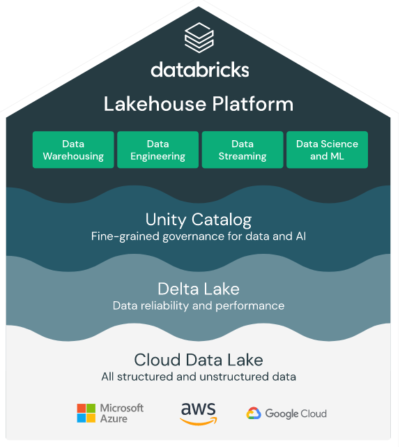 Unternehmen wie Amgen, AT&T, Northwestern Mutual und Walgreens entscheiden sich für das Lakehouse, weil es die Möglichkeit bietet, Analysen sowohl für strukturierte als auch für unstrukturierte Daten durchzuführen. Databricks stellt neue Data-Warehousing-Funktionen in seiner Plattform vor, um die Analyse-Workloads weiter zu verbessern:
Unternehmen wie Amgen, AT&T, Northwestern Mutual und Walgreens entscheiden sich für das Lakehouse, weil es die Möglichkeit bietet, Analysen sowohl für strukturierte als auch für unstrukturierte Daten durchzuführen. Databricks stellt neue Data-Warehousing-Funktionen in seiner Plattform vor, um die Analyse-Workloads weiter zu verbessern:
- Databricks-SQL-Serverless, das in der Vorschau auf AWS verfügbar ist, bietet sofortige, sichere und vollständig verwaltete elastische Rechenleistung für verbesserte Leistung zu geringeren Kosten.
- Photon, die leistungsfähige Abfrage-Engine für Lakehouse-Systeme, wird in den kommenden Wochen allgemein auf Databricks-Workspaces verfügbar sein und damit die Reichweite von Photon auf der Plattform weiter ausbauen. In den zwei Jahren seit der Ankündigung von Photon wurden Exabytes an Daten verarbeitet, Milliarden von Abfragen ausgeführt und ein Benchmark-Preis/Leistungsverhältnis erzielt, das bis zu 12-mal besser ist als das traditioneller Cloud-Dat- Warehouses.
- Open-Source-Konnektoren für Go, Node.js und Python machen es jetzt noch einfacher, von operativen Anwendungen aus auf das Lakehouse zuzugreifen.
- Databricks-SQL-CLI ermöglicht es Entwicklern und Analysten jetzt, Abfragen direkt von ihren lokalen Computern aus auszuführen.
- Databricks-SQL bietet jetzt Query-Federation und damit die Möglichkeit, Remote-Datenquellen wie PostgreSQL, MySQL, AWS Redshift und andere abzufragen, ohne dass die Daten zunächst aus den Quellsystemen extrahiert und geladen werden müssen.
Data-Governance wird mit erweiterten Funktionen für Unity-Catalog als höchste Priorität hervorgehoben

Unity-Catalog ist jetzt allgemein auf AWS und Microsoft-Azure verfügbar und bietet eine zentralisierte Governance-Lösung für alle Daten und KI-Assets, mit integrierter Suche und Erkennung, automatisierter Datenabfolge für alle Workloads sowie Leistung und Skalierbarkeit für ein Lakehouse in jeder Cloud. Darüber hinaus hat Databricks Anfang dieses Monats Data-Lineage für Unity-Catalog eingeführt, was die Data-Governance-Funktionen im Lakehouse erheblich erweitert und Unternehmen einen vollständigen Überblick über den gesamten Lifecycle von Daten ermöglicht. Mit Data Lineage erhalten Kunden einen Überblick darüber, woher die Daten in ihrem Lakehouse stammen, wer sie wann erstellt hat, wie sie im Laufe der Zeit verändert wurden, wie sie in Data Warehousing- und Data Science-Workloads verwendet werden und vieles mehr.
Verbesserter Datenaustausch durch Databricks-Marketplace und Data-Cleanrooms
Als erster Marktplatz für Daten und künstliche Intelligenz bietet Databricks-Marketplace einen offenen Marktplatz für die Bündelung und den Vertrieb von Daten und Analysewerten. Databricks-Marketplace geht über Marktplätze hinaus, die lediglich Datensätze anbieten, und ermöglicht es Datenanbietern, eine Vielzahl von Assets wie Datentabellen, Dateien, Machine-Learning-Modelle, Notebooks und Analyse-Dashboards sicher zu verpacken und zu vermarkten. Datenkonsumenten können auf einfache Weise neue Daten und KI-Assets entdecken, ihre Analysen beschleunigen und schneller Erkenntnisse und Werte aus Daten gewinnen. Anstatt beispielsweise Zugang zu einem Datensatz zu erhalten und ihre eigene Zeit in die Entwicklung und Pflege von Dashboards zu investieren, um darüber zu berichten, können sie sich einfach für bereits vorhandene Dashboards anmelden, die bereits die erforderlichen Analysen bieten. Databricks-Marketplace wird von Delta-Sharing unterstützt und ermöglicht es Datenanbietern, ihre Daten gemeinsam zu nutzen, ohne dass sie die Daten aus ihrem Cloud-Speicher verschieben oder replizieren müssen. Dies ermöglicht es Anbietern, Daten aus einer einzigen Quelle an andere Clouds, Tools und Plattformen zu liefern.
Databricks unterstützt seine Kunden auch bei der gemeinsamen Nutzung von Daten und der Zusammenarbeit über Unternehmensgrenzen hinweg. Data-Cleanrooms bieten eine Möglichkeit, Daten in einer sicheren, gehosteten Umgebung und ohne Datenreplikation über Unternehmensgrenzen hinweg auszutauschen und zu verknüpfen, wobei der Datenschutz im Vordergrund steht. In der Medien- und Werbebranche möchten beispielsweise zwei Unternehmen die Überschneidung von Zielgruppen und die Reichweite von Kampagnen verstehen. Bestehende Cleanrooms-Lösungen haben ihre Grenzen, da sie in der Regel auf SQL-Tools beschränkt sind und das Risiko der Datenduplizierung über mehrere Plattformen hinweg besteht. Mit Databricks-Cleanrooms können Unternehmen problemlos mit Kunden und Partnern in jeder beliebigen Cloud zusammenarbeiten und ihnen die Flexibilität bieten, komplexe Berechnungen und Workloads sowohl mit SQL als auch mit Data-Science-basierten Tools – einschließlich Python, R und Scala – auszuführen, und zwar mit konsistenten Datenschutzkontrollen.
Machine-Learning und Delta-Live-Tables
Databricks ist mit der Einführung von „MLflow 2.0“ weiterhin führend in der MLOps-Innovation. Um eine Pipeline für maschinelles Lernen in Produktion zu bringen, muss nicht nur Code geschrieben, sondern auch die Infrastruktur eingerichtet werden. Dies kann für neue Benutzer schwierig und für alle Beteiligten mühsam sein. MLflow-Pipelines, ermöglicht durch MLflow 2.0, kümmert sich nun um die operativen Details für die Benutzer. Anstatt die Orchestrierung von Notebooks einzurichten, können Benutzer einfach die Elemente der Pipeline in einer Konfigurationsdatei definieren und MLflow-Pipelines verwaltet die Ausführung automatisch. Über MLflow hinaus hat Databricks auch Serverless-Model-Endpoints hinzugefügt, um das Hosting von Produktionsmodellen direkt zu unterstützen, sowie integrierte Model-Monitoring-Dashboards, um Teams bei der Analyse der realen Modellleistung zu unterstützen.
Delta-Live-Tables (DLT) ist das erste ETL-Framework, das einen einfachen, deklarativen Ansatz für den Aufbau zuverlässiger Datenpipelines verwendet. Seit der Markteinführung Anfang des Jahres hat Databricks DLT um neue Funktionen erweitert, darunter die Einführung einer neuen Leistungsoptimierungsschicht, die die Ausführung von ETL beschleunigen und die Kosten senken soll. Darüber hinaus wurde das neue Enhanced-Autoscaling speziell für die intelligente Skalierung von Ressourcen mit den Schwankungen von Streaming-Workloads entwickelt. Change-Data-Capture (CDC) für Slowly-Changing-Dimensions – Type 2 verfolgt jede Änderung in Quelldaten sowohl für Compliance- als auch für Machine-Learning-Experimente.
#Databricks









{kind=link}