 Unternehmen müssen heute kundenorientiert arbeiten und in der Lage sein, Innovationen schnell auf den Markt zu bringen. Dabei müssen Applikationen hohe Ansprüche an Verfügbarkeit und Performance erfüllen. Ausfallzeiten kann sich niemand leisten, denn die Kundenerwartungen sind hoch. All das erfordert eine flexible, skalierbare IT-Umgebung. Um den unterschiedlichen, wechselnden Anforderungen gerecht zu werden, geht der Trend dahin, mehrere Clouds zu kombinieren. Ob eine Hybrid-Cloud aus Public-Cloud und Private-Cloud oder gar verschiedene Public-Clouds – laut einer aktuellen Studie von 451 Research in 14 europäischen Ländern setzen bereits 84 Prozent eine Kombination aus verschiedenen Cloud-Umgebungen ein.
Unternehmen müssen heute kundenorientiert arbeiten und in der Lage sein, Innovationen schnell auf den Markt zu bringen. Dabei müssen Applikationen hohe Ansprüche an Verfügbarkeit und Performance erfüllen. Ausfallzeiten kann sich niemand leisten, denn die Kundenerwartungen sind hoch. All das erfordert eine flexible, skalierbare IT-Umgebung. Um den unterschiedlichen, wechselnden Anforderungen gerecht zu werden, geht der Trend dahin, mehrere Clouds zu kombinieren. Ob eine Hybrid-Cloud aus Public-Cloud und Private-Cloud oder gar verschiedene Public-Clouds – laut einer aktuellen Studie von 451 Research in 14 europäischen Ländern setzen bereits 84 Prozent eine Kombination aus verschiedenen Cloud-Umgebungen ein.
Mit Big-Data-Analytics und IoT setzen sich zudem Technologien durch, die ein exponenziell wachsendes Datenvolumen und viele verschiedene Datentypen mit sich bringen. Während es Unternehmen früher vorwiegend mit strukturierten Daten zu tun hatten, die man erst sammeln und dann an einer zentralen Stelle analysieren konnte, fließt heute ein kontinuierlicher Strom an unterschiedlichen Datentypen aus IoT-Systemen oder Smartphone-Applikationen herein, zum Beispiel Maschinendaten, Videostreams, Social-Media-Beiträge oder Kundeninformationen. Diese treten an verschiedenen Stellen auf und müssen oft sofort ausgewertet werden.
Relationale Datenbanken stoßen an ihre Grenzen
Sowohl die Hybrid- und Multi-Cloud-Umgebung als auch die veränderte Datenlandschaft stellen neue Anforderungen an das Datenmanagement. Mehr als ein halbes Jahrhundert waren relationale Datenbankmanagement-Systeme das führende Modell. Sie wurden für zentralisierte Workloads designt, eignen sich perfekt für strukturierte Daten und sind äußerst zuverlässig. Dieses Modell ist jedoch nicht mehr zeitgemäß, denn heute arbeiten Unternehmen mit verteilten Workloads und müssen riesige Mengen von teils unstrukturierten Daten speichern und analysieren.
Zunehmend haben sich daher NoSQL-Datenbanken durchgesetzt, kurz für „Not only SQL“. Sie wurden dafür konzipiert, große Volumen an verteilten und auch unstrukturierten Daten in Echtzeit zu verarbeiten, ohne dass man sich dabei Sorgen um Ausfallzeiten machen muss. NoSQLs versprechen horizontale Skalierbarkeit und eine höhere Verfügbarkeit als relationale Datenbanken. Das reicht jedoch nicht aus, denn was Unternehmen heute brauchen, ist kompromisslose Performance und Hochverfügbarkeit. Hier stoßen auch die meisten NoSQL-Datenbanken an ihre Grenzen.
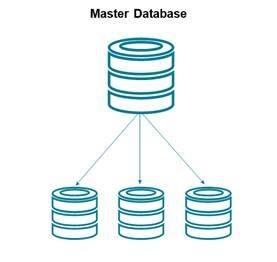
Das Master-Slave-Problem
Viele NoSQL-Datenbanken basieren ebenso wie SQL-Datenbanken auf einer Master-Slave-Architektur. Solche Systeme verfügen über einen Master, auf dem die Datenbank läuft, und Slaves, die mit dem Master verbunden sind. Auf den Slaves können Datenbankabfragen durchgeführt werden, aber nur der Master kann Daten schreiben. Er steuert zudem alle Datenbank-Transaktionen und gibt den Slaves Anweisungen, was sie tun sollen. Eine Master-Slave-Architektur lässt sich skalieren, indem man weitere Slaves hinzufügt. Dadurch kann die Datenbank zwar mehr lesende Zugriffe gleichzeitig abarbeiten, alle schreibenden Aktionen und die Steuerung laufen jedoch weiterhin über den einen Master. Fällt er einmal aus, funktioniert das gesamte System nicht, bis ein neuer Master aufgesetzt ist. Um das zu vermeiden, setzen viele Datenbankkonzepte mehrere Master ein. Doch auch das kann das Problem nur bedingt lösen. Denn mit mehreren Mastern gibt es schlichtweg mehr Punkte, an denen die Datenbank ausfallen kann. Hochverfügbarkeit garantiert dies nicht. Gerade in verteilten Netzwerken wie der Hybrid Cloud sind Master-Slave-Architekturen außerdem äußerst komplex umzusetzen.
Die Lösung: NoSQL-Datenbank mit No-Master-Architektur
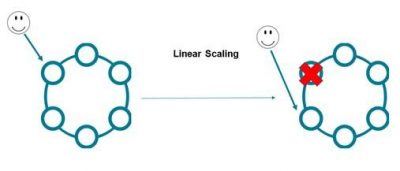
Ein neuer Ansatz für das Datenbankmanagement ist gefragt, der für Hochverfügbarkeit in verteilten Netzwerken sorgt. Dies gelingt mit einer Active Everywhere Database. Dabei handelt es sich um eine NoSQL-Datenbank, die ohne Master auf Basis von Apache Cassandra aufgebaut ist. Jeder Knoten im Cluster ist identisch, autonom und kann sowohl lesende als auch schreibende Transaktionen ausführen. Fällt ein Knoten aus, wird der Datenverkehr automatisch an einen anderen geleitet. Dieser übernimmt die Anfrage nahtlos, ohne dass dafür Code geändert werden muss. Es kommt zu keinerlei Performance-Einbußen. Sobald der ausgefallene Knoten wieder einsatzbereit ist, werden die Daten automatisch mit den anderen Knoten synchronisiert. Ein solches System ist ganz einfach skalierbar, indem man weitere Knoten hinzufügt. Außerdem lässt es sich problemlos auf verschiedenen Clouds und Rechenzentren verteilen. Damit gewinnen Unternehmen einen weiteren Vorteil: Sie sind in der Lage, Datenbanken ganz nach Bedarf von einer Cloud in eine andere oder aus dem Rechenzentrum in die Cloud zu verschieben. Dadurch gewinnen sie mehr Flexibilität und machen sich nicht von einem Anbieter abhängig. Bietet ein anderer Provider ein günstigeres Angebot, können sie ohne großen Aufwand wechseln.
Fazit

Um wettbewerbsfähig zu bleiben, müssen Unternehmen heute in der Lage sein, riesige Mengen an Daten unterschiedlicher Typen zu verarbeiten. Dabei nutzen sie zunehmend Hybrid-Cloud- oder Multi-Cloud-Umgebungen. Das erfordert ein Datenbankmanagement, das sich für strukturierte und unstrukturierte Daten in verteilten Netzwerken eignet und dabei Hochverfügbarkeit garantiert. Mit einer Active Everywhere Database können Unternehmen Daten beliebig auf verschiedene Public-Clouds und On-Premise-Infrastrukturen verteilen. So stehen die Daten jederzeit am richtigen Ort in der geforderten Geschwindigkeit zur Verfügung, um einen reibungslosen Betrieb von Anwendungen und ein positives Kundenerlebnis sicherzustellen.
#Netzpalaver #Datastax











{kind=link}