 Eine Katastrophe ist eine länger andauernde und meist großräumige Schadenlage, die mit der normalerweise vorgehaltenen Gefahrenabwehr nicht angemessen bewältigt werden kann und die nur mit Hilfe und zusätzlichen Ressourcen unter Kontrolle gebracht werden kann. Bei Katastrophen kommt es regelmäßig zum Ausfall der Telekommunikationssysteme; sowohl wegen Überlastung als auch technischer Funktionsunfähigkeit. Mobilfunkanlagen können wie Festnetze beschädigt werden, aber auch bei Stromausfall nach einiger Zeit (trotz vorhandener Notstromsysteme) versagen. Im Falle von IT-Services ist eine Katastrophe der Verlust des Zugangs zu IT-Systemen und Netzwerken. IT-Systeme und Netzwerke sind so wichtig, dass ihr Verlust ein Unternehmen lähmen kann. Lassen sich Katastrophen verhindern? Wenn nicht, was kann getan werden, dass der Ausfall der Systeme reduziert wird? Wie schnell erholen sich die unternehmenskritischen Funktionen nach einem Ausfall?
Eine Katastrophe ist eine länger andauernde und meist großräumige Schadenlage, die mit der normalerweise vorgehaltenen Gefahrenabwehr nicht angemessen bewältigt werden kann und die nur mit Hilfe und zusätzlichen Ressourcen unter Kontrolle gebracht werden kann. Bei Katastrophen kommt es regelmäßig zum Ausfall der Telekommunikationssysteme; sowohl wegen Überlastung als auch technischer Funktionsunfähigkeit. Mobilfunkanlagen können wie Festnetze beschädigt werden, aber auch bei Stromausfall nach einiger Zeit (trotz vorhandener Notstromsysteme) versagen. Im Falle von IT-Services ist eine Katastrophe der Verlust des Zugangs zu IT-Systemen und Netzwerken. IT-Systeme und Netzwerke sind so wichtig, dass ihr Verlust ein Unternehmen lähmen kann. Lassen sich Katastrophen verhindern? Wenn nicht, was kann getan werden, dass der Ausfall der Systeme reduziert wird? Wie schnell erholen sich die unternehmenskritischen Funktionen nach einem Ausfall?
Disaster-Recovery
Der Begriff „Disaster-Recovery“ (auch Notfallwiederherstellung) umfasst die Richtlinien, Verfahren, Technologien und Werkzeuge, die die Wiederherstellung oder Fortsetzung der Technologieinfrastruktur und -systeme nach einer natürlichen oder von Menschen verursachten Katastrophe ermöglichen. Dazu zählt sowohl die Datenwiederherstellung als auch das Ersetzen nicht mehr benutzbarer Infrastruktur, Hardware, und Organisation. Umfassender als Disaster-Recovery ist der Begriff Business-Continuity, der nicht die Wiederherstellung der IT-Dienste, sondern unterbrechungsfreie Geschäftsabläufe in den Vordergrund stellt.
Die Business-Continuity bezeichnet die Entwicklung von Strategien, Plänen und Handlungen, um Tätigkeiten oder Prozesse – deren Unterbrechung einem Unternehmen ernsthafte Schäden oder vernichtende Verluste zufügen würden – zu schützen bzw. alternative Abläufe zu ermöglichen. Die Business-Continuity bezeichnet eine Managementmethode, die anhand eines Lebenszyklus-Modells die Fortführung der Geschäftstätigkeit unter Krisenbedingungen oder zumindest unvorhersehbar erschwerten Bedingungen absichert. Es besteht eine enge Verwandtschaft mit dem Risikomanagement. Um bei Vorfällen beziehungsweise im Katastrophenfall die Abwicklung der Geschäfte eines Unternehmens fortführen zu können müssen Analysen und Planungen vorgenommen werden. Es muss hierfür festgelegt werden, welche Prozesse unbedingt aufrechterhalten werden müssen sowie welche Maßnahmen dafür notwendig sind. Dazu müssen entsprechende Prioritäten definiert und die hierfür benötigten Ressourcen identifiziert werden. Somit ist die Disaster-Recovery ein Teilbereich der Business-Continuity.
Das Business-Continuity-Management sorgt für den Aufbau eines leistungsfähigen Notfall- und Krisenmanagements. Dieses hat die Aufgabe systematisch auf die Bewältigung von Schadenereignissen vorzubereiten, so dass wichtige Geschäftsprozesse selbst in kritischen Situationen nicht oder nur temporär unterbrochen werden und die wirtschaftliche Existenz des Unternehmens trotz Schadenereignis gesichert bleibt. Ziel des Business-Continuity-Managements ist die Definition von Prozessen und deren Dokumentation in Form eines Notfallvorsorgeplans.
Katastrophen lauern überall
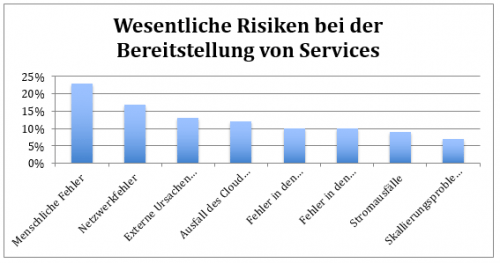 Eine von Cloudendure kürzlich veröffentlichte Umfrage (2017 Disaster Recovery Survey Report) besagt, dass 60 Prozent der befragten Unternehmen über Disaster-Recovery-Fähigkeiten für mindestens die Hälfte ihrer Produktionssysteme verfügen. Das bedeutet, dass nicht jedes Unternehmen die Absicht hat, jeden möglichen Geschäftsprozess abzusichern. Aus diesem Grund muss sich der Planer folgende Frage stellen: „Welche Disaster Recovery-Investitionen zeigen die geringsten Wirkungen?“ Die Grafik „Wesentliche Risiken bei der bereitstellung von Services“ verdeutlicht die Antworten der Cloudendure-Umfrage.
Eine von Cloudendure kürzlich veröffentlichte Umfrage (2017 Disaster Recovery Survey Report) besagt, dass 60 Prozent der befragten Unternehmen über Disaster-Recovery-Fähigkeiten für mindestens die Hälfte ihrer Produktionssysteme verfügen. Das bedeutet, dass nicht jedes Unternehmen die Absicht hat, jeden möglichen Geschäftsprozess abzusichern. Aus diesem Grund muss sich der Planer folgende Frage stellen: „Welche Disaster Recovery-Investitionen zeigen die geringsten Wirkungen?“ Die Grafik „Wesentliche Risiken bei der bereitstellung von Services“ verdeutlicht die Antworten der Cloudendure-Umfrage.
Gemäß der Umfrage machen menschliche Fehler etwa 23 Prozent der Risiken im Bereich der Verfügbarkeit aus. Weitere häufige Probleme sind Netzwerkausfälle (17 Prozent) und externe Bedrohungen (13 Prozent). Überraschend sind die hohen Verfügbarkeitsprobleme der Cloud-Provider (12 Prozent).
In Sachen „Verfügbarkeit“ geistert immer wieder die Zahl 99.XXX Prozent durch die IT-Branche. Achtundzwanzig Prozent von den in der Cloudendure-Studie befragten Unternehmen sagten aus, dass diese Marke ihr angestrebtes Ziel repräsentiere. 15 Prozent der befragten Unternehmen nannten ein Verfügbarkeitsziel von 99,99 Prozent und bei 21 Prozent lag die geplante Verfügbarkeit bei 99,9 Prozent. Diese Ziele bedeuten jedoch nicht, dass die befragten Unternehmen ihre Ziele auch erreichen. Ein Problem bei der Verfügbarkeitsberechnung besteht darin, dass sich diese aus mehrfachen kurzen Katastrophen oder einer riesigen Katastrophe zusammensetzen können und in beiden Fällen die gleichen Zahlen liefern.
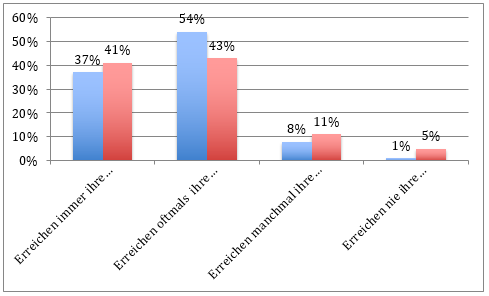
Wie aus der nachfolgenden Grafik hervorgeht, erreichen die Unternehmen ihre Verfügbarkeitsziele zu 41 Prozent der Zeit. Dreiundvierzig Prozent der befragten Firmen erreichen meistens ihre Verfügbarkeitsziele, während 16 Prozent ihre Ziele nur unzureichend oder überhaupt nicht erreichen.
Wie werden die Verfügbarkeitswerte berechnet?
Die Verfügbarkeitswerte errechnen sich aus dem Recovery-Point-Objective (RPO) und dem Recovery-Time-Objective (RTO).
Recovery-Point-Objective (RPO): Der RPO-Wert legt fest, wie viel Datenverlust in Kauf genommen werden kann. Bei der Recovery Point Objective handelt es sich um den Zeitraum, der zwischen zwei Datensicherungen liegen darf, das heißt, wie viele Daten/Transaktionen dürfen zwischen der letzten Sicherung und dem Systemausfall höchstens verloren gehen. Wenn kein Datenverlust hinnehmbar ist, beträgt der RPO-Wert 0 Sekunden. Bei 26 Prozent der befragten Unternehmen beträgt der RPO-Wert zwischen 6 bis 59 Minuten. Es überrascht, dass 32 Prozent der Befragten einen RPO von mehr als einer Stunde nennen und 10 Prozent der teilnehmenden Unternehmen zugeben, dass sie nicht wissen, was der RPO-Wert überhaupt bedeutet. In die Praxis übersetzt bedeutet der RPO-Wert: Je größer dieser Wert, desto mehr Informationen gehen verloren.
Recovery-Time-Objective (RTO): Der RTO-Wert legt fest, wie lange ein Geschäftsprozess/System ausfallen darf. Bei der Recovery-Time-Objective handelt es sich um die Zeit, die vom Zeitpunkt des Schadens bis zur vollständigen Wiederherstellung der Geschäftsprozesse (Wiederherstellung der Infrastruktur und der Daten, der Nacharbeitung der Daten und der Wiederaufnahme der Aktivitäten) vergehen darf. Der Zeitraum kann hier von 0 Minuten (Systeme müssen sofort verfügbar sein), bis mehrere Tage (in Einzelfällen Wochen) betragen.
Vier Prozent der Befragten gaben an, dass in ihrem Unternehmen ein RTO mit dem Wert = 0 festgelegt ist. Die überwiegende Mehrheit (30 Prozent) der Teilnehmer an der Umfrage gehen von einer Erholungszeit von 6 bis 59 Minuten aus. Weitere 21 Prozent der Teilnehmer können mit einer Erholungszeit von 1 bis 6 Stunden leben. Insgesamt 26 Prozent kennen nicht ihre RTO-Werte oder dieser ist größer als sieben Stunden.
Test der Disaster-Recovery-Lösung
Die Absicherung der Geschäftsprozesse gehört zu den vordringlichsten Aufgaben des IT-Betriebs. Manchmal passieren manche Dinge einfach und gegen Unfälle ist man nicht gefeit. Eine solche Erkenntnis entbindet uns jedoch nicht vor einer gewissen Planung. Was immer auch passieren mag, es ist gut, wenn man sich bereits darauf vorbereitet hat. Es ist wie beim Fahrradfahren. Man trägt einen Helm, nicht um damit besonders komisch auszusehen, sondern weil man mit dem Schlimmste plant und sich schützen will.
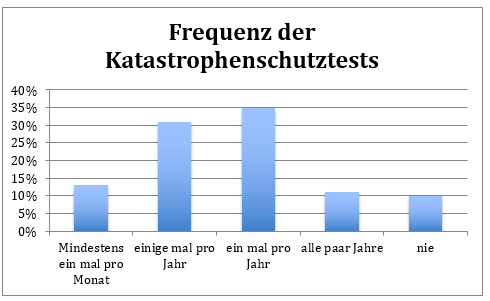 Eine Binsenweisheit lautet daher: Die Disaster-Recovery-Lösungen müssen regelmäßig getestet werden. 79 Prozent der befragten Unternehmen gaben an, dass sie mindestens einmal im Jahr eine Disaster-Recovery Übung durchführen. Einundzwanzig Prozent der Unternehmen testen ihren Disaster-Recovery-Plan alle paar Jahre oder führen keine praktischen Tests durch.
Eine Binsenweisheit lautet daher: Die Disaster-Recovery-Lösungen müssen regelmäßig getestet werden. 79 Prozent der befragten Unternehmen gaben an, dass sie mindestens einmal im Jahr eine Disaster-Recovery Übung durchführen. Einundzwanzig Prozent der Unternehmen testen ihren Disaster-Recovery-Plan alle paar Jahre oder führen keine praktischen Tests durch.
Trotz der besten Absichten der Hersteller, Designer, Installateure, Service-Provider, IT-Manager und Techniker gehen die besten Pläne manchmal einfach schief. Die Geräte fallen aus, die Leitungen werden durchtrennt, angeblich harmlose Änderungen bringen ganze Systeme zum Kollaps und die Naturgewalten haben die unangenehme Angewohnheit, uns daran zu erinnern, wer der Chef ist. Winzige Störungen können lästig sein, während größere Unterbrechungen zu Umsatzeinbußen, unzufriedenen Kunden, Produktivitätsverlusten und in extremen Fällen zu Verlusten von Menschenleben führen können.
Aus diesem Grund kann ein Test pro Jahr nicht genug sein, denn die Netzwerke und die daran angeschlossenen Systeme ändern sich sich im Laufe eines Jahres und ein einziger Test kann unter Umständen zu einer falschen Einschätzung der Verfügbarkeitslage führen.
Plane das Undenkbare
Die Industrie stellt und viele Bausteine zur Errichtung einer voll-redundanten Lösung zur Verfügung. Die Kosten und Komplexität einer redundanten Lösung hängen davon ab, welches Risiko ein Unternehmen bereit ist zu akzeptieren. Als Faustformel zur Erhöhung der Verfügbarkeit kann folgende (unvollständige) Liste dienen:
- Es sollten so viele Fehlerquellen wie möglich beseitigt werden. Dazu gehören Redundanzen bzw. Mechanismen zur Erhöhung der Verfügbarkeit bei den Routern, den Call-Servern, den Netzwerken, den Session Border Controllern, den Session-Management-Servern, etc. Das Ziel muss darin bestehen, dass jemand mit einem Vorschlaghammer auf die Geräte einschlägt, ohne dass das Unternehmen ein Telefonat verliert.
- Mehrere Carrier/Provider verbessern den Brei! Es ist äußerst selten, dass bei zwei Carriern/Providern gleichzeitig in einen bestimmten regionalen Bereich deren Dienst ausfallen. Selbst bei großen Naturkatastrophen bleibt der eine oder andere Carrier/Provider noch in Betrieb, während andere bereits ihren Betrieb einstellen.
- Auch für die Netzwerke sollte eine Ausfallsicherung vorgesehen werden. Dies gilt sowohl für die kabelgebundenen als auch für die drahtlosen Netzwerke. Besonders in Zweigstellen sollte darauf geachtet werden, dass die Verbindung zum Carrier/Provider über drahtlose Technologien (beispielsweise 4G/LTE) im Katastrophenfall genutzt werden kann.
- Der Wechsel auf SIP ist Pflicht. Neben möglichen Kosteneinsparungen bietet SIP robustere Disaster-Recovery-Varianten als die klassische TDM-Technologie. Das Leistungsmerkmal „Mehrfachabstützung“ (also redundante Anschlüsse der TK-Anlagen zu unterschiedlichen Verteilzentren bzw. Providern) war zwar in der ISDN-Welt vorgesehen, wurde aber oft von den Anbietern nicht unterstützt. Die VoIP-Lösungen gehen inzwischen sehr viel weiter als es ISDN je konnte, da die bei der klassischen Telefonie entstehenden Taktprobleme entfallen.
- Nutzen Sie die Möglichkeiten der Cloud. Die Redundanzmöglichkeiten der heute angebotenen Cloud-Lösungen im Kommunikationsbereich sind fast nicht mehr zu überschauen. Man kann beispielsweise die Cloud ausschließlich für die Absicherung der Geschäftsprozesse bei größeren Ausfällen verwenden oder man lagert alle Kommunikationsprozesse in die Cloud aus. Ein solcher Lösungsmix kann Leitungszuführungen der traditionellen Carrier und Internet- bzw. SIP-Trunks von Providern enthalten. Die Cloud wird heute in den unterschiedlichsten Geschmacksrichtungen angeboten. Aus diesem Grund ist es wichtig, dass ein Unternehmen die richtige und zu ihm passende Cloud-Strategie ausarbeitet.
Fazit

Bei der Planung eines umfassenden Katastrophenschutzes muss auch das Nicht-IT-Personal der verschiedenen Abteilungen im Unternehmen einbezogen werden. Das für die Katastrophenabwehr bereitgestellte Budget muss sich an den möglichen Unternehmensverlusten orientieren, die durch ein unerwartetes Ereignis verursacht werden können. Einige Verluste lassen sich in Euro oder Dollar ausdrücken, während beispielsweise Image- oder Reputationsverluste schwer zu beziffern sind. Es kann schwierig sein, das Unternehmensmanagement von der Notwendigkeit einer umfassenden Desaster-Planung und dem notwendigen Budget für eine ausreichende Notfallwiederherstellung zu überzeugen. Daher müssen alle Planzahlen auf entsprechenden Fundamenten basieren.











{kind=link}