 Was ist Ihre liebste „An meinen Problemen ist nur das Netzwerk schuld“-Anekdote? Wenn Sie ein Netzwerker sind, dann haben Sie wahrscheinlich viele solcher „Dummheiten“ gehört. Natürlich wird bei allen Missständen im Leben immer zuerst das Netz beschuldigt. Inzwischen geht es anderen Bereichen der IT ähnlich. Die Administratoren im Citrix- und Vmware-Umfeld werden abwechselnd als „die neuen Netzwerk-Typen“ bezeichnet. Ähnlich einem Dilbert-Cartoon, kann das Stigma auf fast jeden Administrator in der IT angewendet werden.
Was ist Ihre liebste „An meinen Problemen ist nur das Netzwerk schuld“-Anekdote? Wenn Sie ein Netzwerker sind, dann haben Sie wahrscheinlich viele solcher „Dummheiten“ gehört. Natürlich wird bei allen Missständen im Leben immer zuerst das Netz beschuldigt. Inzwischen geht es anderen Bereichen der IT ähnlich. Die Administratoren im Citrix- und Vmware-Umfeld werden abwechselnd als „die neuen Netzwerk-Typen“ bezeichnet. Ähnlich einem Dilbert-Cartoon, kann das Stigma auf fast jeden Administrator in der IT angewendet werden.
Gehören Sie einem App-Team an oder gehören zu den Vertretern der klassischen Nutzer in ihrem Unternehmen, dann sollten Sie jetzt an die jüngsten IT-Beschwerden denken. Haben Sie, möglicherweise ohne klares Verständnis der tatsächlichen Ursache, die Schuld auf das Netzwerk geschoben? Natürlich unterstellt ihnen keiner eine böse Absicht. Die Schuld an der Misere kann immer auf das Netzwerk geschoben werden und das Netz ist irgendwie zum Sündenbock für alle Unpässlichkeiten bzw. zum Gradmesser der Leistungsfrustration geworden.
Ich kümmere mich intensiv seit mehreren Jahrzehnten um die Netzwerk- und die Sicherheitstechnologien. Aufgrund meiner Wurzeln in der Netzwerkwelt reagiere ich manchmal übermäßig empfindlich, wenn das Netzwerk für ein ineffizientes Verhalten einer Anwendung beschuldigt wird. Ich versuche diese Vorbehalte mit einer gesunden Skepsis gegenüber der Qualität der Netzwerkservices zu relativieren und muss doch zugegen, manchmal liegt das Problem wirklich am Netzwerk.
Wenn das Netzwerk selbst Probleme macht, weil ein Router zusammenbricht und es nicht mehr möglich ist, die Pakete zuverlässig weiterzuleiten, dann muss das Netzwerk repariert werden (und vielleicht die Redundanz des Gesamtsystems verbessert werden). Aber solche einfachen und eindeutigen Fälle sind heute sehr selten geworden. Es sind viel eher die subtilen, unerwarteten Interaktionen zwischen den Anwendungen und den Netzwerken, die die Benutzer verärgern und zu unqualifizierten Aussagen (das Netzwerk ist wieder einmal zu langsam) hinreißen. Dies gilt in zunehmendem Maße auch für Netze mit Firewalls, alle Arten von Bereitstellungsplattformen für Applikationen, Mechanismen zur Optimierung der WANs, eigentlich allen Komponenten, die oberhalb der Schichten 2 und 3 arbeiten und irgendwie mit den Anwendungen in Berührung kommen.
Ich finde es hilfreich, diese Probleme als Konflikte zwischen Netzwerk- und Anwendungsdesign zu betrachten. Unabhängig davon, ist es nicht unbedingt schlecht, dass die beiden Welten (Anwendung und Netzwerk) optimal zusammenarbeiten. Gibt es in diesem Bereich Probleme, kann sich das verheerend auf ein Unternehmen auswirken.
Warum gibt es kein perfektes Netzwerk?
Warum können wir nicht einfach ein perfektes Netzwerk bauen? Ich werde (zumindest vorübergehend) argumentieren, dass es so etwas wie ein perfektes Netzwerk nicht gibt. Es gibt so lange kein perfektes Netzwerk, wie man nicht weiß, welche Art von Anwendungsverkehr transportiert werden soll.
Zunächst wollen wir die üblichen Lösungsmechanismen, den Ruf nach mehr Bandbreite und geringer Verzögerung, verwerfen. Ein Netzwerk mit unbegrenzter Bandbreite und keiner Verzögerung gibt es nicht! Darüber hinaus gilt es zu akzeptieren, dass ein Netzwerk mit einer extrem kurzen Verzögerung (Latenz ≤ 0) nicht mehr die IT-Ressourcen in den Büros der Niederlassungen erreichen kann. Wir müssen auch akzeptieren, dass die Bandbreite in den vergangenen Jahrzehnten immer preiswerter geworden ist, aber immer noch ein gewisses Entgelt kostet. Dies gilt insbesondere bei Strecken über große Entfernungen oder Strecken, die nationale Grenzen überschreiten.
Was wäre, wenn das Netzwerk nur Telnet oder modernere Thin-Client-Protokolle (ICA oder PCoIP) unterstützen würde? Damit wären klare Designkriterien festgelegt: Eine endliche Menge an Bandbreite pro gleichzeitigem Benutzer mit einer maximalen Verzögerungszeit von 150 Millisekunden zwischen dem Endgerät des Benutzers und dem jeweiligen Server. Soll ein Netzwerk zur reinen Sprachübermittlung entworfen werden, dann bestehen möglicherweise größere Bandbreitenanforderungen, ähnliche Beschränkungen im Bereich der Verzögerungen, aber man würde den Jitter zusätzlich in die Designüberlegungen einbeziehen. Was wäre im Netzwerk notwendig, um einen Batch-Job zu entwerfen, der 200 GByte monatlich zu einem Offline-Speicher in Sao Paulo übermittelt? Vielleicht wäre die optimale Lösung für diesen Anwendungsfall, ein USB-Sticks der per Post zum Ziel geschickt würde. Zusammengefasst bedeuten meine Ausführungen: Verschiedene Anwendungstypen und die von ihnen genutzten Protokolle weisen unterschiedliche Empfindlichkeiten gegenüber den Netzwerkcharakteristiken wie verfügbare Bandbreite, Verzögerung und Jitter auf.
Können wir nicht alle Anforderungen vereinheitlichen?
Selbstverständlich bauen wir in der Regel keine Netzwerke für nur einen Anwendungszweck. Auch spielen Performance-Überlegungen für eine bestimmte Anwendung beim Netzdesign eine untergeordnete Rolle. Häufige Beispiele für diese Designkriterien sind die QoS-Mechnismen, das Caching und die Content-Distribution-Networks (CDNs) sowie die verschiedenen WAN-Optimierungstechniken, die die Datentransfervolumina senken, die TCP-Overheads reduzieren und das Anwendungsverhalten durch Spoofing optimieren. Diese Zusatzfunktionen tragen zur Verbesserung der Anwendungsleistung und der Qualität der Netzwerkdienste bei. Der Schlüssel zu einer optimalen Performance liegt in der richtigen Planung. Im Umkehrschluss bedeutet diese Aussage jedoch: Schlecht geplante Netzwerke oder nicht optimal umgesetzte Änderungen, die eigentlich die Leistung des Netzwerks verbessern sollen, können negative Konsequenzen auf die zu transportierenden Anwendungsströme haben.
Die Verbesserung der Performance einer Anwendung im Netz profitiert extrem vom Verständnis der wahrscheinlichen Interaktionen. Dieses Verständnis trägt auch zur Optimierung bei der Fehlerbehebung bei, da die Funktionen der Anwendungen nicht durch unrealistische Annahme definiert werden.
Netzwerkerei in der Praxis
Vor nicht allzu langer Zeit analysierte ich ein Performance-Problem bei einem meiner Kunden. Der Server-zu-Server-Durchsatz war viel geringer als erwartet und selbst die Diagnosedaten wurden auf der Übertragungsstrecke nicht unerheblich verzögert. Der Hersteller der Anwendung versicherte uns, dass es sich mit ziemlicher Sicherheit um einen Netzwerkfehler handeln müsse, da Hunderte von Kunden bisher die Anwendung ohne Probleme nutzen würden. Auch bei meinem Kunden hatte früher alles einwandfrei funktioniert, bis der Server in einem anderen Rechenzentrum installiert wurde. Das Einzige was anders war, war das Netzwerk.
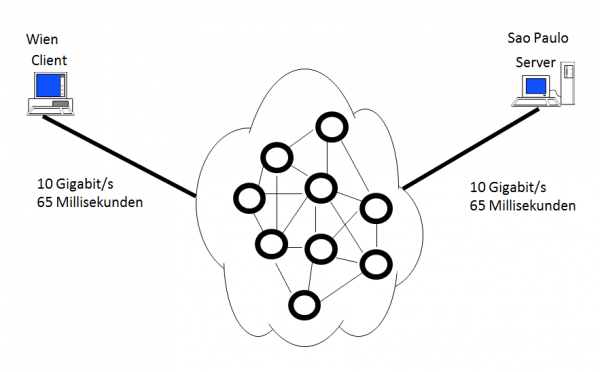
Ich weiß, dass bestimmte Anwendungen und TCP-Protokolle unter Umständen ein bestimmtes Verhalten aufweisen können, was zu einer Performance-Verschlechterung (durch eine zunehmenden Netzwerklatenz) führen kann. Daher stellte ich meinen IT-Ansprechpartnern folgende einfachen Fragen:
- Frage 1: Steht die neue Verzögerung in Einklang mit der bei der neuen Entfernung der Standorte zur erwarteten Verzögerung? (Ich gehe hier von einem simplen Routing-Problem aus).
- Antwort 1: Ja. 65 Millisekunden für jeweils den Hin- und den Rückweg entsprechen der ungefähren Distanz.
- Frage 2: Wie gesprächig ist die Anwendung? Um wie viele Anwendungen handelt es sich? Wie viele Bytes werden bei jeder Anfrage von der betreffenden Applikation übermittelt?
- Antwort 2: Die Applikation übermittelt ihre Dateien in Blöcken von bis zu 512 KByte. Bei jedem Schreibvorgang wird jeder übermittelte Datenblock mit einem Acknowledge-Paket bestätigt.
- Frage 3: Welche Größe weist das TCP-Fenster des empfangenden Knotens auf?
- Antwort 3: Keine Ahnung.
- Frage 4: Übermittelt die Anwendung die Daten im Blockmodus oder im Stream-Modus an das Socket-Interface (von welchen die Übertragung über das Netzwerk ausgeht).
- Antwort 4: Stream-Modus (ein File nach dem anderen).
Ich bin immer überzeugt, dass das Netzwerk die beste Quelle für Diagnosedaten ist. Aus diesem Grund fragte ich meine IT-Ansprechpartner nach einem entsprechenden Trace-File. Da diese nicht vorlagen untersuchten wir die Verbindung mit Hilfe eines Wireshark-Analysators. Bereits die erste Analyse bestätigte meine Vermutung: Das TCP-Empfangsfenster war erheblich eingeschränkt.
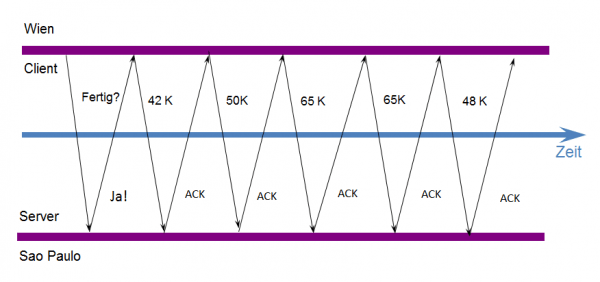
Selbst bei aktivierter TCP-Fenster-Skalierungsoption erreicht das Empfangsfenster nie eine Größe > 65 KByte. Dadurch wird das Überlastungsfenster (Congestion-Window) des Senders immer auf 44 Pakete begrenzt. Der Entwickler der Anwendung gab uns dann Hinweise zur Lösung des Problems: Die Anwendung weist der Verbindung immer einen Empfangspuffer von 128 KByte zu. Ich erinnerte mich wieder daran, dass Anwendungen beim Öffnen einer Socket-Verbindung ihre eigene Empfangspuffergröße festlegen können. Dieser Wert geht für eine Server-zu-Server-Kommunikation in Ordnung und funktionierte auch für die meisten abgesetzten Verbindungen (wenn der Server in einem Remote-Netz installiert ist). Es gibt jedoch eine Bedingung: Die zu übertragende Datei muss klein sein. In unserem Netzwerk verfügten wir jedoch über eine hohe Bandbreite, einer hohen Verzögerung und einem relativ hohen Verkehrsvolumen durch andere Anwendungen. Der kleine Puffer, welcher von der Anwendung festgelegt wurde, resultiert in diesem Fall in einer ineffizienten TCP-Flusssteuerung, was die Performance-Probleme erklärt.
Wo liegt das Problem?
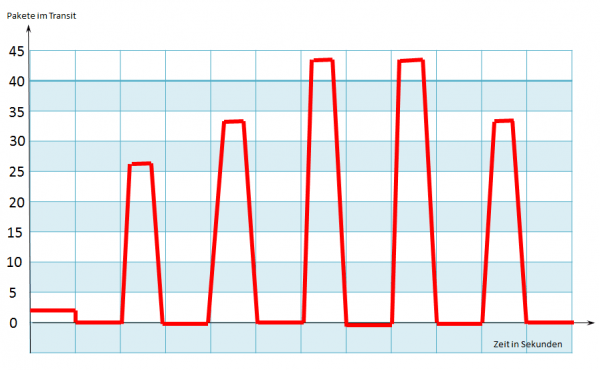
Handelt es sich bei den beschriebenen Symptomen um ein Netzwerkproblem oder ein Anwendungsproblem? In der Praxis sind meist beide Problembereiche eng miteinander verknüpft. Die Ursachen für ein Performance-Problem liegen nie allein in der Netzinfrastruktur, noch in der Anwendung. Daher muss man sich die Frage stellen, ob man überhaupt die Leistung verbessern kann, indem man entweder am Netzwerk oder der Anwendung herumdoktert. Unserem Beispiel deutet als Ursache für die schlechte Performance auf eine physische Ursache (Netzwerkverzögerung) hin. Bei genauer Analyse erkennt man jedoch, dass die Anwendung (durch die zu kleine TCP-Fenstergröße) direkte Auswirkungen auf die Performance hat. Aus diesem Grund empfiehlt Gartner eine enge und direkte Zusammenarbeit der Anwendungs- und der Netzverantwortlichen. Nur so können eventuelle Probleme bereits in der Entstehung beseitigt werden. (mh)











{kind=link}